
The life of a developer is often incredibly rewarding. We get to take an idea for an app or software that doesn’t currently exist and bring it to life through code! However, that’s not to say there isn’t a fair share of headaches acquired along the way, but if it were easy everyone would be doing it. For this particular writeup, we are going to focus on the creation of neural networks (the foundation of machine learning) and how to overcome potential issues that may arise when creating them.
Neural networks are like any project, they take a significant amount of time and energy to get just right. In this example, we are getting ready to push a complex solution for image classification. Just as we feed the network an image for classification, low and behold it spits out the wrong answer (of course). What happens now?
Usually, the team gathers around and shouts a million and one suggestions (“it must be the blue in the background”, “mercury is in retrograde”, or an office favorite, “maybe remove the labels!”). While some of these suggestions are testable, the effort needed to verify these features isn’t necessarily feasible. Even if there isn’t anyone shouting suggestions, we still find ourselves scrambling around using instinct and experience to diagnose the problem. The end result could be tons of wasted cycles spent guessing at solutions and then testing them again.
Or perhaps a wonderful network is built that passes all the tests created for it. It’s proudly presented it to a client only to have them ask, “how can we trust it?”. One way is pointing to all the tests the neural network completed and present various metrics, but unless the clients are already well versed in Machine Learning, they won’t feel very satisfied.
Instead, in a second scenario, we again have constructed a fully functional network and it again passes all tests, solving the client’s problem. But then someone asks “what have we learned?” Beyond predicting some value, how can we use this network to help plot future strategy?
In the first case, we hope to see light at the end of a seemingly endless cycle of guess and check that usually accompanies network development. We want to understand why a network made its decision and use that to guide our experiments.
In the second case, we seek to provide another measure of the network’s success and seek to bolster “confidence” in its decisions. One of the reasons people love algorithms like SVMs, Nearest Neighbor, or Linear/Logistic Regression is that the training algorithms output some data structure that can be easily examined. There are a few coefficients or exemplars that can be pointed to or visualized. One can easily say how a model makes its decisions and show that they are explainable. With Neural Networks, we don’t get that benefit right away.
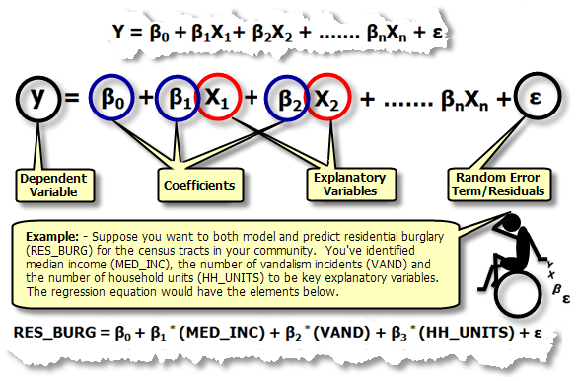
One of the reasons why linear models and the like are so popular in the Social Sciences is that experimenters want to both predict their dataset accurately and know the reason in regard to the underlying data structure. Which variable is likely to predict student success? Does the variable have the same effect for two sub-populations? If we want to boost sales, which strategy is more likely to succeed? These are questions that are easy to answer if there are any coefficients. Not so with a neural network.
Feature Visualizations And Attribution

These are the two biggest subfields of neural network understanding. In traditional machine learning, we typically refer to features as the direct input to our learning algorithm — which can be viewed as a pipeline. Start with raw data, transform that data into features, and then run the machine learning algorithm. For example, in face detection, it was the standard to first run edge detection on an image to produce an image of edges, then feed that image to the machine learning algorithm. Generally, the selection of features was a carefully considered part of the process and was often called feature engineering.
In today’s deep networks, the process of feature engineering is one of the tasks that the network must accomplish. The choice of features is something that the network is supposed to learn through training. The theory is that the lower-level layers in the model learn features like edge detection while the upper levels learn more abstract concepts. How true is that? That is the question that feature visualization is supposed to answer. This is usually done by taking a group of neurons within a network and deriving a picture of inputs that lead to group activation. Is there a picture of what typically makes this group of neurons happy? The hope is that these pictures will reveal which features were learned. For example, when examining select neurons in GoogleNet, researchers generated an image for a group of neurons that looks suspiciously like a dog’s ear. They reasoned that these neurons were a dog ear detector.
Attribution asks the question, “which portions of the input are responsible for the network’s response?” When the inputs are graphical images, the question changes to what portion of the input image are most influencing the eventual outcome of the network. The hope here is to produce a graphic that highlights which image portions the network “pays attention to” and which parts drive network decisions.
Thankfully, there has been a lot of work done in these areas. In one hour of searching, we managed to find some 50 academic papers on the subject and several blog posts. While these papers are fascinating and fun to read, they don’t answer the practical question of “how useful are these ideas and tools?” Can these concepts be used in a production environment? Do they meet the business needs outlined above?
The Questions We Want To Answer

We find current theoretical and mathematical research quite fascinating. However, we have practical work that involves getting Deep Neural Networks to perform specific tasks. We would like to see if any of these insights and tools are going to help us with that. Can these tools actually tell us what is wrong or right with our network? Will this knowledge actually help us to build a better network?
To that end, we propose a set of ongoing experiments. First, we will find a small enough object classification dataset. We will then construct a small network that attempts to classify the dataset. This network will have some flaws. We will then try out various neural understanding methods and see if it helps us do our job and fix our network. Along the way, we intend to release as much code as we can (no proprietary technology) as well as HOW TOs and tutorials on these techniques. We will also try to explain the techniques in a simple way. Our hope is to demonstrate the relative usefulness of these techniques and give you the tools to use them in your own workflows. To that point, don’t forget to follow us on social media as we release our findings!






